


CoreWeave: Fundamental Deep Dive
As part of our weekly fundamentals, we deep dive CoreWeave, a leading AI Hyperscaler.

Hey Fundamental Investors,
Jon here from Artemis. As we previously mentioned in our last weekly fundamentals, two of the largest secular tailwinds are:
Proliferation of AI and the seemingly infinite demands for GPUs
Proliferation of stablecoins as a global payment rail.
We wrote about Circle’s pre-IPO Financial Model here (which is now public at $30B) and today we deep dive CoreWeave, a $67B market cap public AI Hyperscaler.
CoreWeave is an important stock to understand for digital asset investors that are anticipating and excited about potential token launches from Nous Research (decentralized AI and open source models on Solana) and Prime Intellect (decentralized AI compute aggregator looking to transform into a peer to peer AI protocol). CoreWeave is in some sense a centralized version of these businesses on the GPU / compute provider side.
Fundamental investors are desperate for exposure to tokens and equities that give direct exposure to the growth of AI and we believe CoreWeave is an important company to study.
Let’s dive into CoreWeave with our fundamental analyst, Kevin Li.
Summary of CoreWeave
As monetization in the AI stack transitions from semiconductors to cloud infrastructure, CoreWeave is emerging as a central player in this next wave of value capture.
CoreWeave initially differentiated itself by removing the hypervisor layer, running Kubernetes directly on bare metal. It then expanded its advantage by developing a full-stack platform focused on automation, observability, and reliability for large-scale AI model training.
Customers choose CoreWeave because of its proven ability to deliver large-scale GPU clusters with high reliability, in-depth observability tools, and full automation—all while meeting the highest standards for security and support.
CoreWeave’s core business model revolves around long-term, fixed-price contracts with large enterprise customers. These contracts typically span up to 4-6 years and are backed by upfront payments, which CoreWeave uses—along with external financing—to purchase and deploy GPU infrastructure.
A major strategic advantage lies in CoreWeave’s close relationship with NVIDIA, which enables it to secure early access to next-generation GPUs (e.g., H200, GB200) and bring them to market faster than any competitor. This early access gives CoreWeave an edge in locking down long-term, high-value deals before supply becomes widely available.
The unit economics of a modern "neocloud" provider like CoreWeave depend on three primary known drivers: GPU pricing (per hour), cost of capital (interest rates and financing terms), and operational efficiency (utilization rates, infrastructure scaling).
While CoreWeave currently faces customer concentration risk—with a large share of revenue tied to OpenAI and Microsoft Azure—it is actively diversifying. This includes moving up the AI stack, as demonstrated by its acquisition of Weights & Biases, a widely adopted MLOps platform. This strategic move expands CoreWeave’s distribution and brings in new customers ranging from startups to individual ML developers.
The AI Revolution and Value Accrual
Ever since the advent of ChatGPT and GPT-3.5 in the fall of 2022, the world has undergone transformative change. These models demonstrated remarkable generalizability and the ability to handle unstructured data, signaling a fundamental shift in how humans interact with machines and data. Large Language Models (LLMs) have positioned themselves as catalysts of the sixth technological revolution. The pace of innovation has only accelerated. Model efficiency has soared while compute costs have dropped by more than 90%, all while the intelligence and capabilities of these models have dramatically increased.
Yet, despite these advances, the pattern of value capture in the AI era initially seems to be starkly different from that of the internet/cloud era—a shift articulated well by Altimeter’s Appoorv Agrawal. During the internet era, application companies like Adobe and Salesforce captured around 60% of the value, infrastructure providers (cloud platforms) about 30%, and semiconductor companies (like AMD and Intel) just 7.5%. In contrast, the generative AI era has flipped this dynamic. Semiconductors—led by Nvidia—now capture over 83.3% of the value. Infrastructure (AI cloud) captures 11.1%, while application-layer companies (like OpenAI and Midjourney) capture only 5.6%. The central question is whether this trend will persist, or if value will eventually migrate downstream.
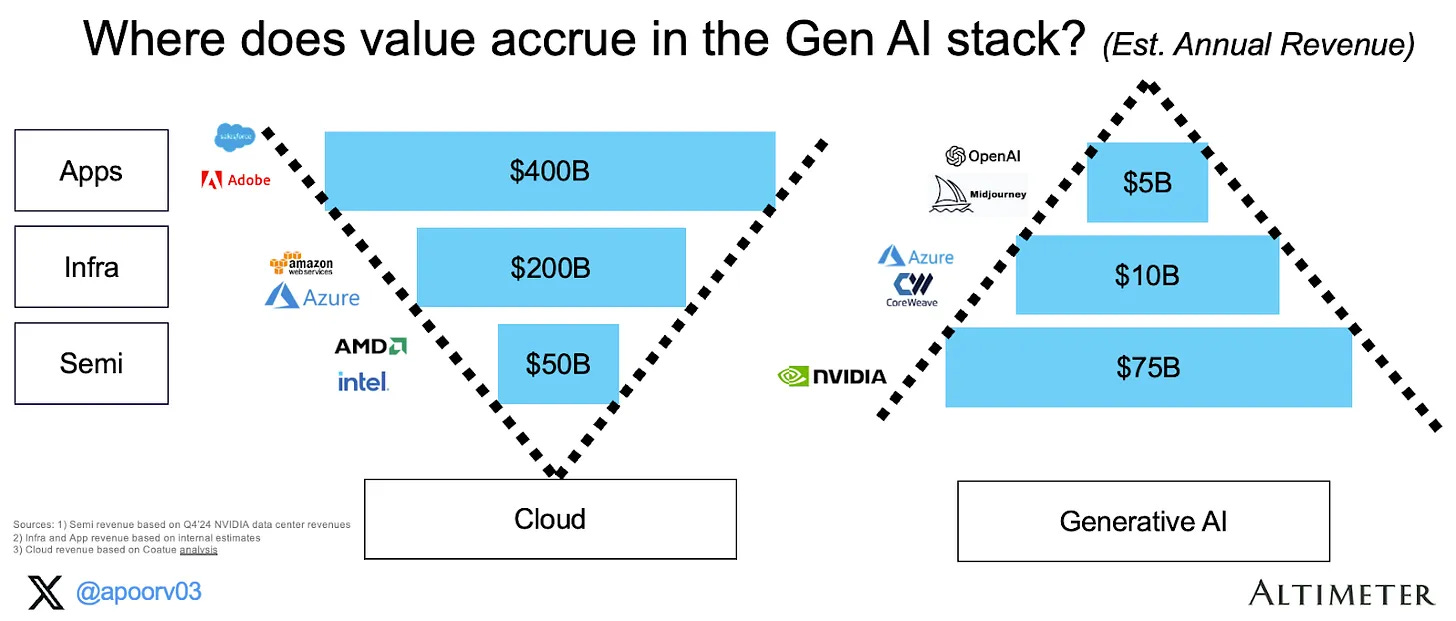
However, if we look to history, we can observe a repeating pattern of value flowing from energy sources to infrastructure, and eventually to the application layer. Thus the current value flow is not uncommon, but actually normal. This framework is evident in prior technological revolutions:
Third Technological Revolution (Industrial Age - Electrification)
Energy: Electricity
Infrastructure: Steel
Applications: Factories and production lines
Fourth Technological Revolution (Oil Age - Automotive/Consumer Products)
Energy: Oil
Infrastructure: Highways and gas stations
Applications: Automobiles, airplanes, home appliances
Fifth Technological Revolution (Digital Age)
Energy/Processing: Microprocessors, servers, batteries
Infrastructure: Computers, smartphones, cloud computing
Applications: Internet services, mobile apps, cloud-based platforms
This progression is mirrored by stock performance and monetization cycles observed throughout the digital age.
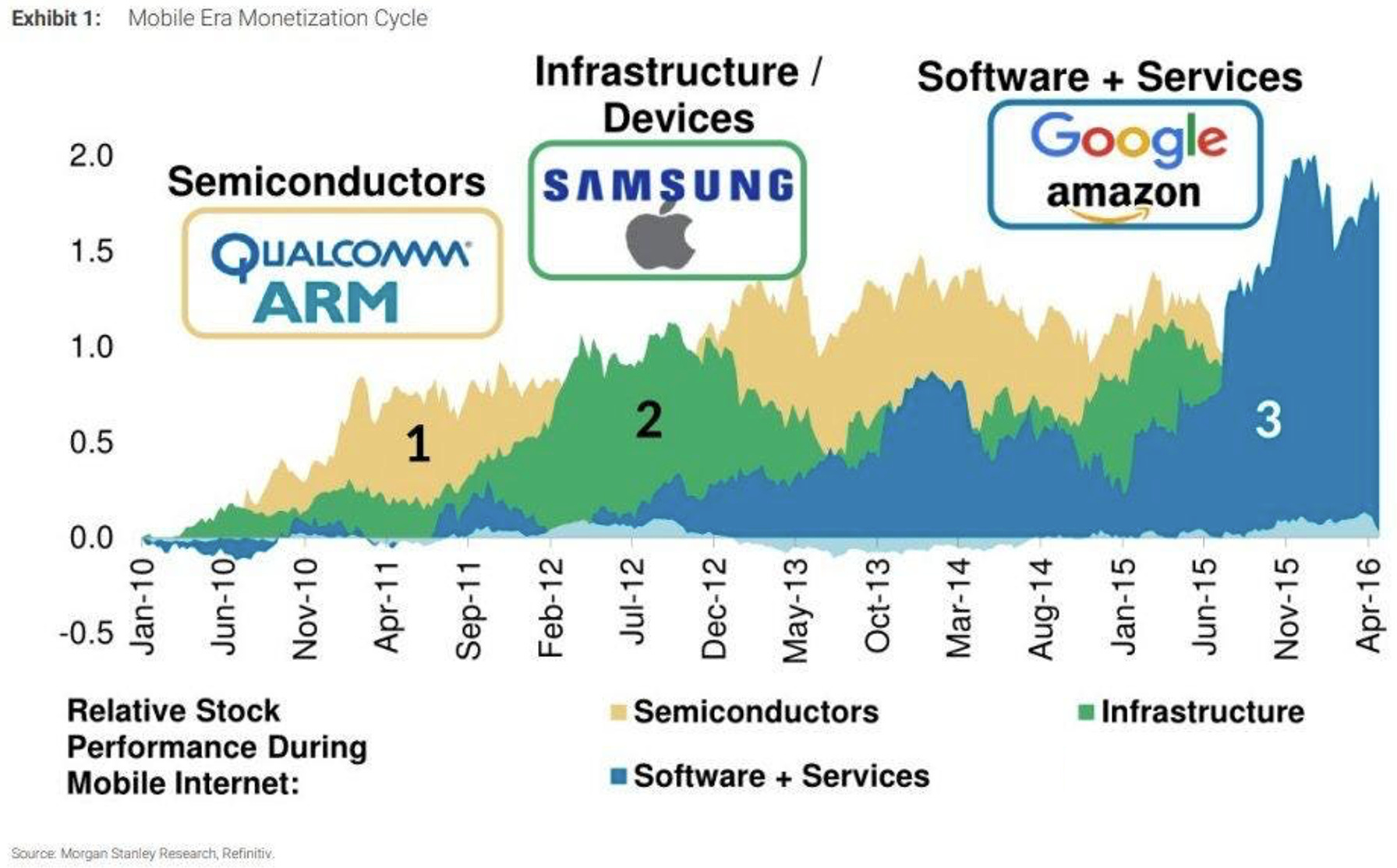
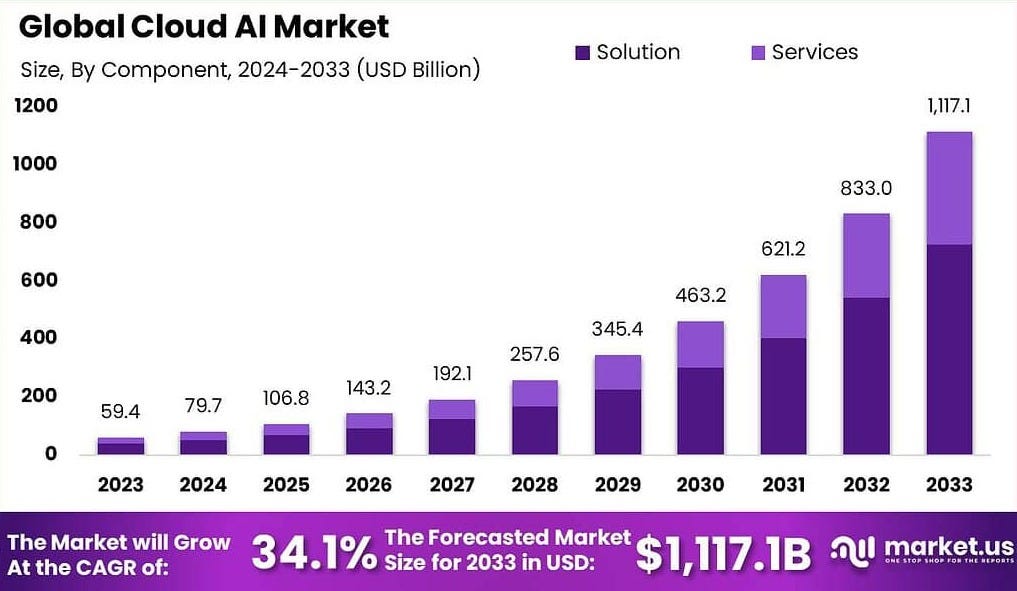
With the emergence of reinforcement learning - models like DeepSeek R1, and applications such as Deep Research and Manus, we are likely entering the infrastructure monetization phase of the AI revolution. This implies an exponential rise in compute demand—driven by both training and inference—and token utilization. This places immense strategic importance on AI-native cloud providers who are the backbone infrastructure distributor of this new compute-driven AI economy. Value is shifting from semiconductor companies to the cloud and model infrastructure layer. According to Market.US, the Global Cloud AI Market Size, is expected to grow from ~$80B to ~$1110B by 2033, compounding at a CAGR of 34.1%.
Introduction to CoreWeave:
At the heart of this booming industry is CoreWeave, the largest AI-native cloud provider and a rapidly rising star in the AI compute space. CoreWeave built its reputation on reliably managing large GPU clusters with high performance—expertise originally developed during its early days operating Ethereum mining farms. Unlike traditional hyperscalers (big cloud providers), CoreWeave stands out by serving high-profile clients such as OpenAI, Meta AI, Jane Street, and Microsoft. It is the only non-hyperscaler capable of reliably operating massive GPU clusters, currently managing over 250,000 GPUs across its global infrastructure.
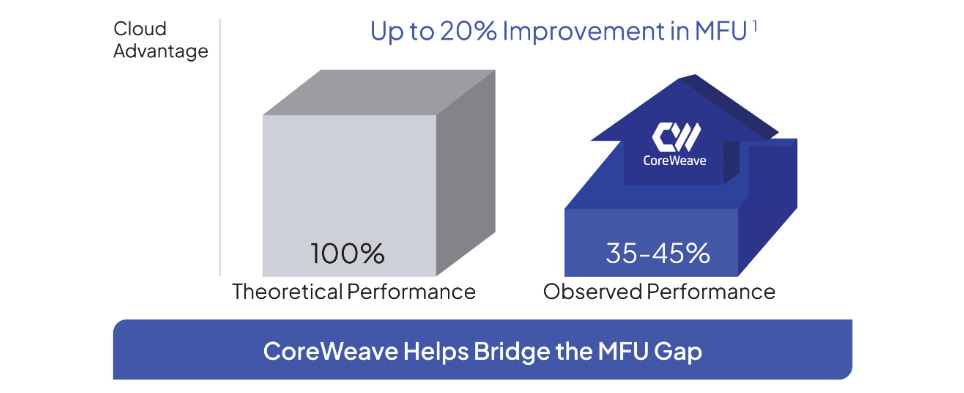
What differentiated and jump-started CoreWeave was a simple architectural choice: instead of using a hypervisor—a common layer of software that manages virtual machines in most cloud environments—CoreWeave ran workloads directly on physical hardware. This eliminated unnecessary overhead and allowed for faster, more efficient performance, especially for compute-heavy tasks like AI training. Think of this as similar to cooking directly on the stove instead of placing another pan on top first—you get more heat, faster results, and fewer layers to slow things down. This approach led to up to a 20% improvement in how effectively the hardware is used (known as Machine FLOPs Utilization), meaning CoreWeave’s systems can get more done with the same equipment. It also enabled a breakthrough in 2023, when CoreWeave trained an AI model 29× faster than competing solutions.
Why Customers Choose CoreWeave:
Customers choose CoreWeave as their compute provider for several key reasons.
First, while CoreWeave offers raw bare-metal infrastructure, its managed services significantly simplify the process of training and deploying AI models. These services have made life much easier for AI engineers—so much so that, as one Amazon VP noted, “Junior engineers could push to prod… on AWS we’d need a 15-person K8s team.” Similarly, the CEO of Cerebrium highlighted CoreWeave’s speed, saying it can spin up GPUs in “four to eight seconds, [while] AWS [needed] ninety-plus” (AlphaSense expert call with Amazon VP, 11 April 2025).
Currently, CoreWeave offers one bare metal and three core managed services to its customers:
Bare Metal: This offering provides raw access to GPU infrastructure without any managed software. Only two customers—OpenAI and NVIDIA—use this service. OpenAI chose it to have full control over the GPUs and, most importantly, to protect their models and intellectual property. Nvidia uses it for in-house development because it lets them run their own tools and custom setups exactly how they want.
Managed Services:
Managed Kubernetes: CoreWeave’s Kubernetes Service (CKS) is a fully managed system built for running large AI workloads, like training language models. It gives users fast access to GPUs, strong security, and clear visibility into how systems are performing—all without needing to manage the setup yourself. This service is ideal for teams that run training jobs in containers, deploy real-time AI features, or manage full machine learning pipelines.
Managed Slurm: This is CoreWeave’s high-performance training environment, ready to use out of the box. It’s designed for teams that need a lot of computing power to train large models. The system handles job scheduling, keeps hardware running smoothly, and scales as needed. CoreWeave takes care of the technical operations, so your team can stay focused on model training.
SUNK: SUNK combines the strengths of both Slurm and Kubernetes into one platform. It lets you run training jobs and serve models in production on the same infrastructure. This helps teams save resources and makes things easier to manage. It’s especially useful for those who need to do both LLM training and real-time AI work without switching environments.
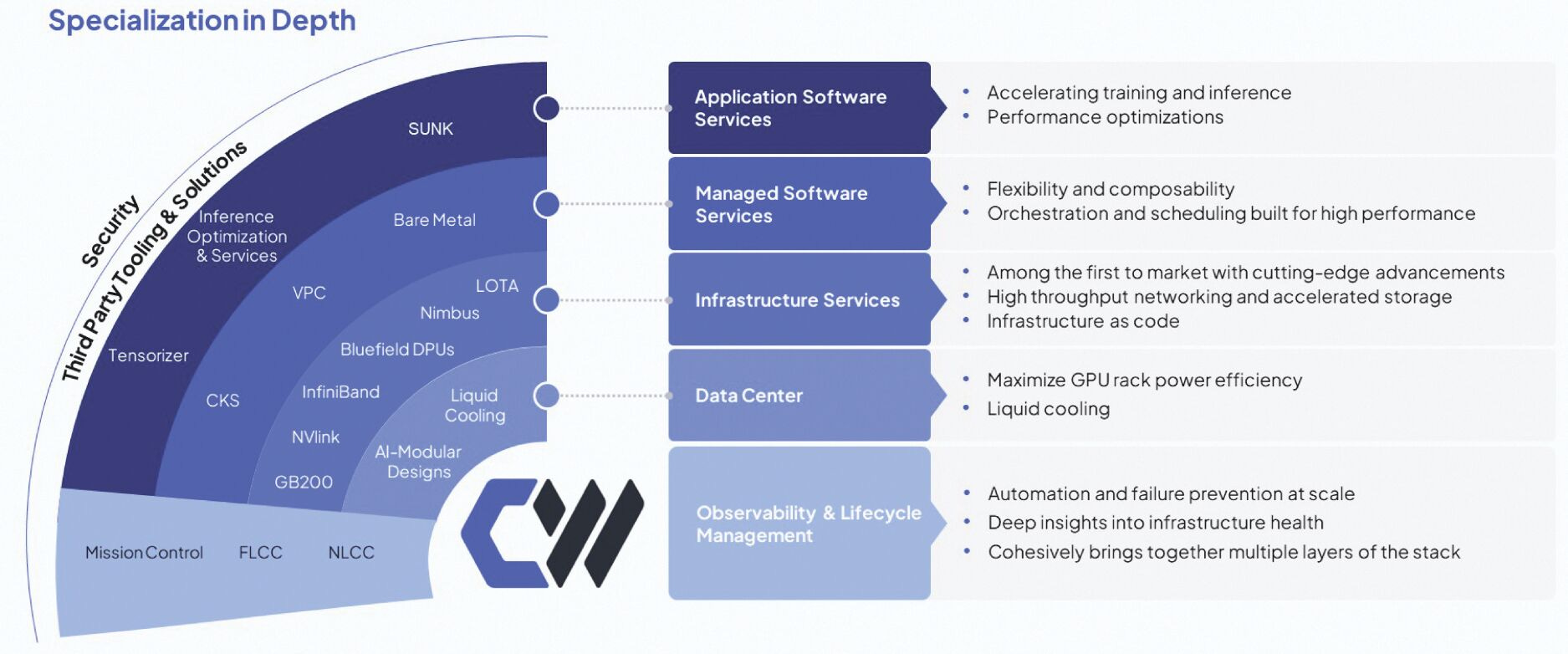
Furthermore, customers value CoreWeave not just for performance and services, but for its reliability.
“If I’m requesting several hundred-thousand pieces of information at the same time, I don’t have to worry about… knock[ing] the cluster over … there’s a smooth spin-up and spin-down and the system health is checked on and maintained by their outer deployment layer” (AlphaSense expert call with a Latitude engineer, May 19, 2025)
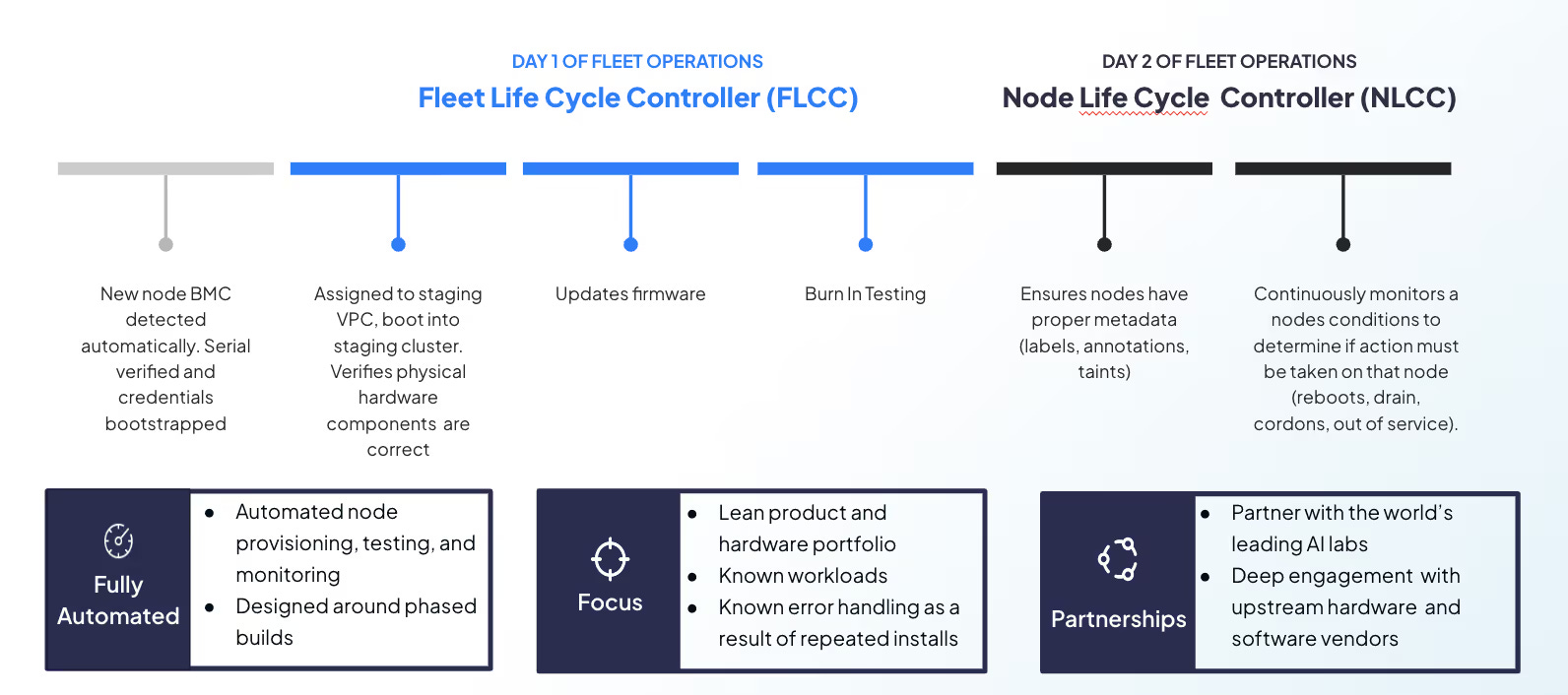
This level of reliability is made possible by CoreWeave’s integrated Mission Control and Observability systems. These tools give teams real-time insight into how their infrastructure is performing and automate many of the complex tasks that come with managing large-scale AI workloads. As clusters grow to support bigger models and more data, keeping everything healthy and running smoothly becomes harder—but also more important. CoreWeave simplifies this challenge by automatically monitoring, maintaining, and optimizing its infrastructure to ensure high availability and performance.
Mission Control consists of two core components that ensure GPU nodes run smoothly:
Fleet Lifecycle Controller (FLCC): Think of this as a “precheck” before a GPU server goes into production. It runs thorough hardware tests—checking things like bandwidth, GPU communication, and system stability—to make sure the server is ready to handle demanding workloads.
Node Lifecycle Controller (NLCC): This is like a “during check,” constantly monitoring servers that are already in use. It keeps an eye on critical components like GPUs, memory, and networking, and replaces anything that starts to fail—before it causes downtime or slows down performance.
Furthermore, CoreWeave’s Observability platform provides deep insight into the real-time and historical performance and health of infrastructure:
Passive Health Checks: These are lightweight background checks that run every few seconds, continuously monitoring for early signs of hardware issues—such as memory errors, PCIe faults, InfiniBand disruptions, or GPU-related anomalies. Think of them as an early warning system, helping identify problems before they impact performance.
Active Health Checks: These are more intensive diagnostic tests that run on idle machines. They include stress tests like GPUBurn and bandwidth validation to ensure the hardware is performing reliably under load. Active checks are designed to uncover hidden or “silent” failures that might not show up during normal use.
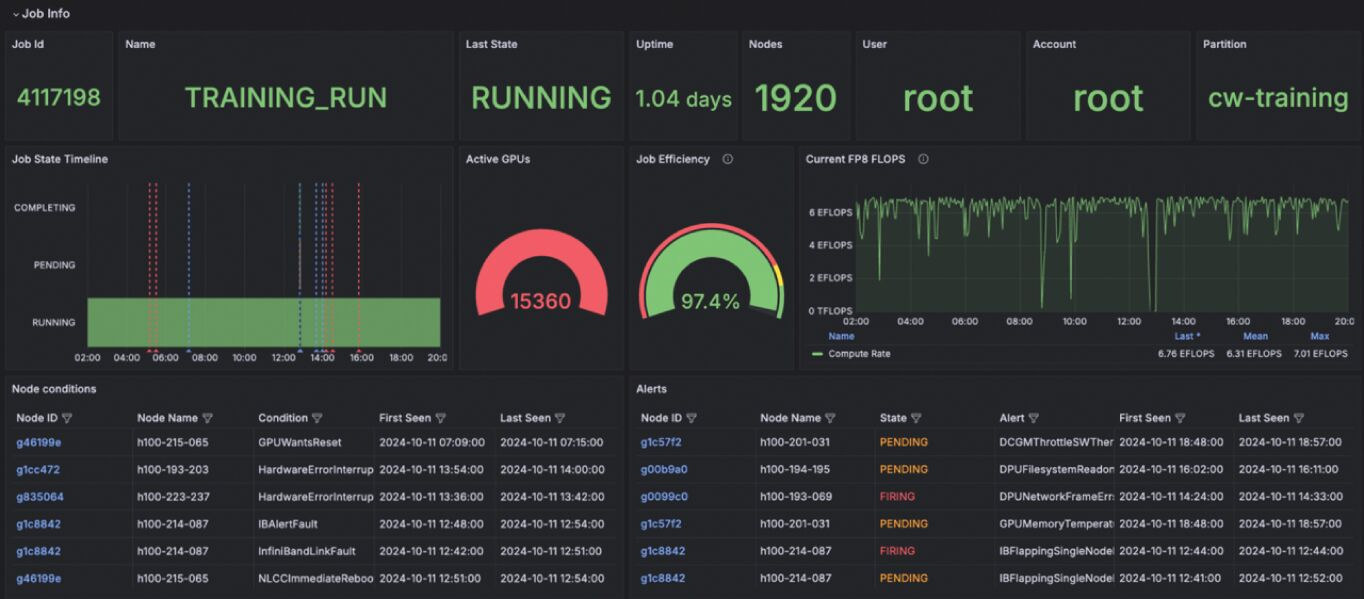
This level of observability is highly valued by customers. As the previously mentioned Amazon VP noted, they appreciated the ability to track details like “CPU temp, as well as our expected spend—15, 30 days, the quarter…” Thus, CoreWeave’s Observability platform focuses on monitoring and detecting issues across the infrastructure, while Mission Control is responsible for acting on that data—automating provisioning, health management, and lifecycle operations for GPU nodes.
In addition to its product advantages, CoreWeave offers top-tier, technically rigorous onboarding and support. Each customer is paired with a dedicated expert engineer who can quickly diagnose and resolve low-level infrastructure issues. As the Amazon VP also noted, “The absolute best customer support I’ve ever seen from a cloud service provider.” Likewise, the engineer from Latitude commented, “It was never difficult to get on a call with an engineer within an hour or so.”
Most importantly, enterprise customers place the highest priority on security. With proprietary IP, model weights, and sensitive data hosted in the cloud, robust protections are critical. As a General Manager at Supermicro noted during an AlphaSense expert call on May 25, 2025: “Tenant isolation and certifications like SOC 2 or ISO 27001 still matter—those are the boxes enterprises tick first.” CoreWeave meets these needs with certifications such as SOC 2 and ISO 27001, and enforces true tenant isolation by providing each customer with a dedicated Kubernetes cluster, ensuring complete separation of data and workloads.

Finally, CoreWeave offers highly competitive pricing compared to traditional cloud providers, while also delivering superior reliability and infrastructure automation. As the CEO of Cerebrium remarked during an AlphaSense expert call on May 26, 2025: “The second reason was their pricing was great compared to clouds like AWS, which is what we previously ran on.” This sentiment was echoed by the engineer from Latitude, who stated: “I find the pricing to be fairly competitive, especially once we got into spend agreements with them over fixed periods of time.”
Understanding CoreWeave’s Business Model
CoreWeave operates on long-term contracts—typically lasting up to 6 years—with fixed pricing. When a customer signs a contract, they make an upfront prepayment. CoreWeave uses this prepayment, along with additional financing, to purchase GPUs and infrastructure. Once the hardware is delivered, there’s an installation period of about 3 months. After that, CoreWeave begins delivering compute services and charging customers monthly. Revenue is recognized evenly over the life of the contract. Toward the end of the contract, the customer’s initial prepayment is applied as credit. Once the contract ends, CoreWeave can reuse the same GPUs for either a new multi-year contract or flexible, on-demand usage by other customers. Importantly, all GPU financing is backed by the revenue from these signed contracts.
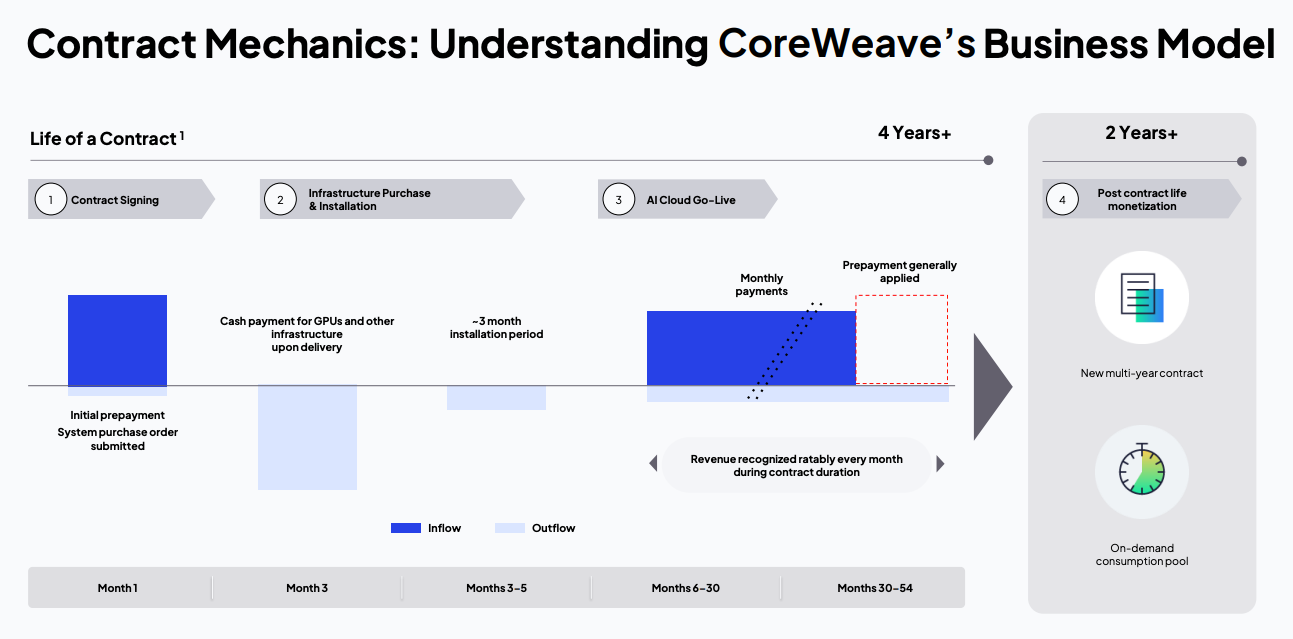
Breaking Down CoreWeave's Unit Economics
Let’s examine the rough unit economics for CoreWeave to understand the key drivers behind its business model. In practice, it's difficult to precisely break down CoreWeave’s full unit economics because the exact GPU mix (e.g., H100, H200, GB200) is unknown, as is the pricing structure CoreWeave uses in its long-term contracts. In general, cloud providers typically face two primary cost categories:
Capital Expenditures (CapEx) — investment in GPUs and supporting infrastructure
Depreciation Cost - annualized reduction in value of hardware over its useful life
Operational Expenditures (OpEx) — primarily electricity and interest expense
CapEx Breakdown: H100 Cluster
Total CapEx: $264,000
Number of H100 GPUs: 8
Cost per H100 GPU: $25,000
Total GPU Cost: $25,000 × 8 = $200,000
Infrastructure Cost per GPU: $8,000
Total Infrastructure Cost: $8,000 × 8 = $64,000
Revenue Breakdown: H100 Cluster
Number of GPUs: 8
Price per GPU-hour: $3
Hours per Year: 8,760
Utilization Rate: 90%
Total Annual Revenue: 8×3×8,760×0.90= $189,216
Cost Breakdown
Electricity Costs (Annual)
Hours per Year: 8,760
Utilization Rate: 90%
Electricity Cost Formula: Power (kW/GPU) * Utilization Rate * Hours per Year * Cost per kWh * Number of GPUs
Calculation: $3,311.29
Interest Expense (Year 1)
Debt Financed: $264,000
Interest Rate: 12%
Annual Interest: 264,000×0.12= $31,680
Depreciation
Depreciation Term: 5 years
(While CoreWeave suggests 6 years, industry consensus for cloud hardware depreciation is typically 5 years. This also aligns with the contract term.)
Annual Depreciation: 264,000÷5= $52,800
Unit Economics: 5-Year Contract Analysis
With these numbers, here is the economics for a 5-year contract assuming the rate is fixed at $3 per hour for an 8-GPU cluster. The economics are quite favorable at this rate. The IRR on capital invested is 12.4%.
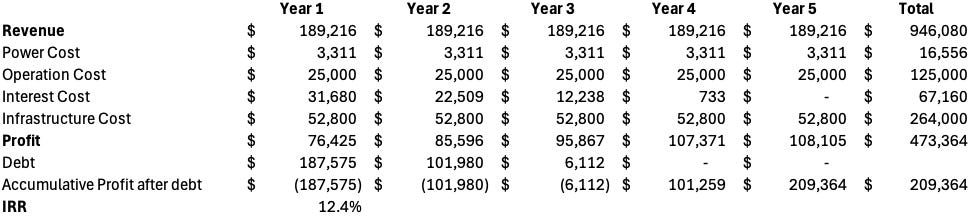
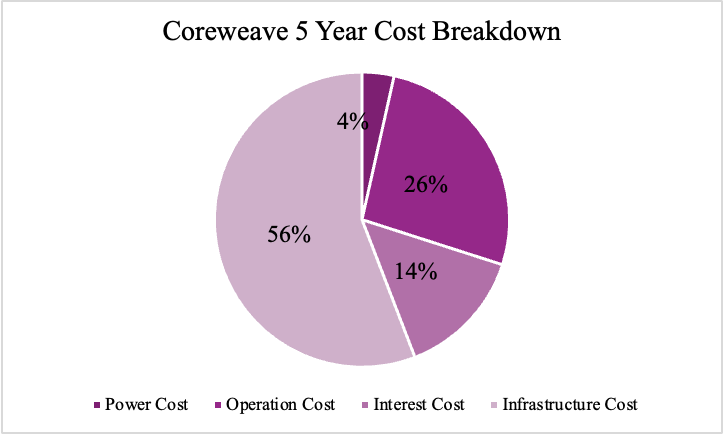
The cost breakdown of the 5-year contract reveals that 56% of the total expenditure is allocated to capital expenditure, primarily infrastructure. Interest payments account for 14%, while operational costs make up 26%. Only 4% of the expenses are attributed to power costs, indicating that electricity is not a major factor in the overall cost structure. This highlights the presence of strong economies of scale—by increasing the volume of hardware ordered, one can gain greater pricing leverage on infrastructure, operational efficiency, and power consumption.
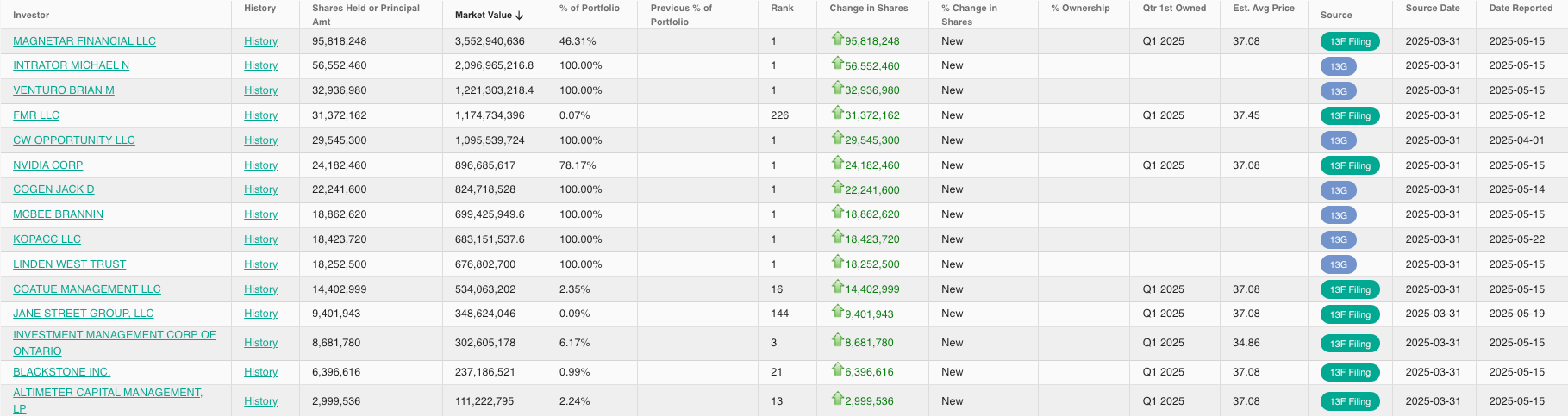
Strategic Partnership — Nvidia as a Moat
While CoreWeave’s product is among the best in the industry, its partnership with Nvidia is what truly sets it apart from other cloud providers. Nvidia has been a significant financial backer of CoreWeave, participating in multiple private funding rounds and serving as an anchor investor for its IPO. According to WhaleWisdom, Nvidia currently holds approximately 24.18 million shares, representing around 5% ownership of the company, making it the sixth-largest shareholder.
Secondly, Nvidia and CoreWeave conduct joint engineering tasks. As mentioned above, CoreWeave currently provides the bare-metal infrastructure for Nvidia, and the two companies collaborate to maximize the efficiency of GPU clusters. Any new improvement in the software layers typically appears on CoreWeave’s systems first. When Nvidia needs to test large clusters, CoreWeave is their go-to partner.
Third—and most importantly—due to the reasons outlined in the first and second points, CoreWeave gains early access to new chips and is able to bring them to market ahead of competitors. This is because the setup for these large clusters is extremely hard and infrastructure required for each new generation of chips can vary significantly. For example, the rack density and cooling requirements changed from A100 to H100, and the transition from H100 to GB200 required liquid cooling technology. These infrastructure upgrades take time and cannot happen overnight. Therefore, by working closely with Nvidia during the testing phase, CoreWeave is able to prepare in advance. This is evidenced by CoreWeave being the first cloud provider to offer GB200s, helping them secure major contracts with IBM, Mistral AI, Cohere, and OpenAI.
Being first to market is extremely important for two key reasons. Firstly, most large AI companies are in intense competition and are willing to buy the latest compute hardware in large quantities—regardless of cost—to stay ahead. This is demonstrated by OpenAI’s $11B contract with CoreWeave, as well as partnerships with MetaAI and reportedly Google. Second, Nvidia’s rapid pace of innovation means that compute costs decrease dramatically each year. New hardware is priced at a premium when first released, with prices falling as Nvidia scales supply and introduces newer architectures. For instance, the GB200s are so powerful that they significantly outperform the H100s. By being first to market with the latest chips, CoreWeave is able to lock in long-term, high-value contracts with hyperscalers and leading AI model developers that no other neocloud provider can accomplish.
To understand the importance of locking in fixed rates early, we modeled a scenario using spot pricing. Assuming a 10% annual decline in H100 rental prices starting from $3.00 per hour in year one, the price would fall to $2.70 in year two, $2.43 in year three, $2.19 in year four, and $1.97 in year five. This mirrors the A100’s historical price trend and highlights a key challenge for spot-based providers: rapidly shrinking margins. In our simulation, if CoreWeave had relied on spot prices instead of fixed contracts, its return on invested capital would decline from 12.4% to 2% over five years, essentially making the business barely profitable. One key takeaway is that CoreWeave’s partnership with Nvidia isn’t merely optional—it forms the core of CoreWeave’s competitive moat.
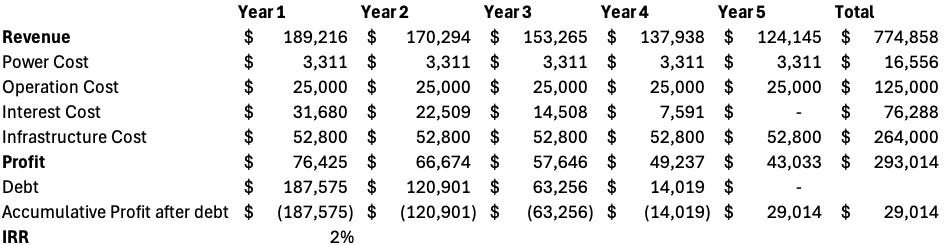
Competitive Advantage 2: Cost of Capital + Economies of Scale
CoreWeave’s second major advantage lies in its role as Nvidia’s leading neocloud partner and the strength of its customer base. Because its financing is tied to tenant credibility, high-quality customers allow CoreWeave to secure lower interest rates. Its public listing further enhances credibility, reducing the cost of capital even more. Additionally, CoreWeave benefits from economies of scale—larger operations drive down per-unit costs for labor and infrastructure. In contrast, smaller neocloud providers face higher capital costs and weaker operational efficiency.
To demonstrate this, we modeled a smaller-scale operator scenario: increasing the interest rate from 12% to 15%, and raising both operational and infrastructure costs by 10%. Assuming a fixed revenue of $3.00/hour—though in reality, most neo-cloud providers are price takers and rarely achieve such stable or high pricing—the average annual return (ARR) dropped from 12.4% to just 7%.
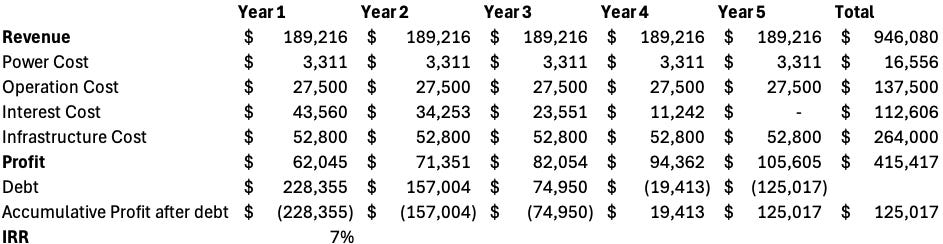
These charts highlight why most neocloud providers struggle economically. There’s a common concern that this is a commodity business—providers are price takers in the spot market, weighed down by high financing costs and limited scale. After analyzing the numbers, it’s clear that offering GPU-based cloud infrastructure is an asset-heavy, capital-intensive model that generally yields poor returns. Returns on capital are highly sensitive to falling GPU prices and elevated interest rates. However, CoreWeave stands out due to its first-to-market advantage, operational scale, and favorable financial structure. That said, any long-term outlook still hinges on GPU pricing, which remains a critical unknown.
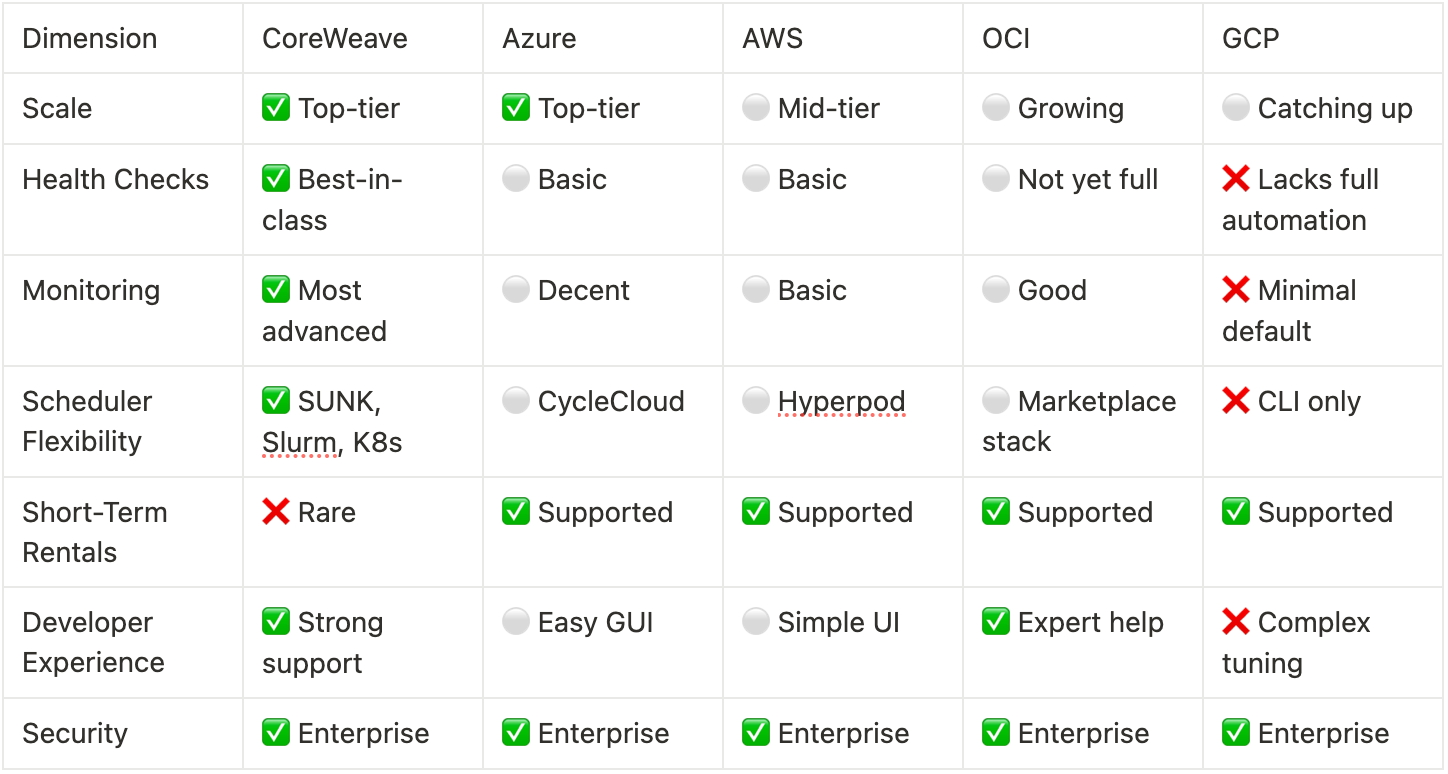
Competitive Positioning (vs Hyperscalers)
CoreWeave is highly competitive with traditional hyperscalers by focusing exclusively on GPU infrastructure. As mentioned above, CoreWeave offers unmatched health check automation, deep observability, and active triage systems—features that hyperscalers like Azure (Microsoft’s Cloud Platform), AWS (Amazon’s Cloud Platform), and GCP(Goggle’s Cloud Platform) largely lack or provide only in basic forms. Its support model is also tailored specifically for ML scientists, with dedicated support engineers and pre-optimized container workflows.
In contrast, hyperscalers offer broader flexibility, including short-term rental options, easier GUI-based deployment (e.g., Azure’s CycleCloud), and comprehensive enterprise integrations. Azure leads in massive-scale AI hosting, while OCI(Orcale’s Cloud Platform) provides strong value and networking. Still, for users prioritizing reliability, transparency, and high-performance GPU workloads, CoreWeave delivers a more focused and robust solution for AI compute.
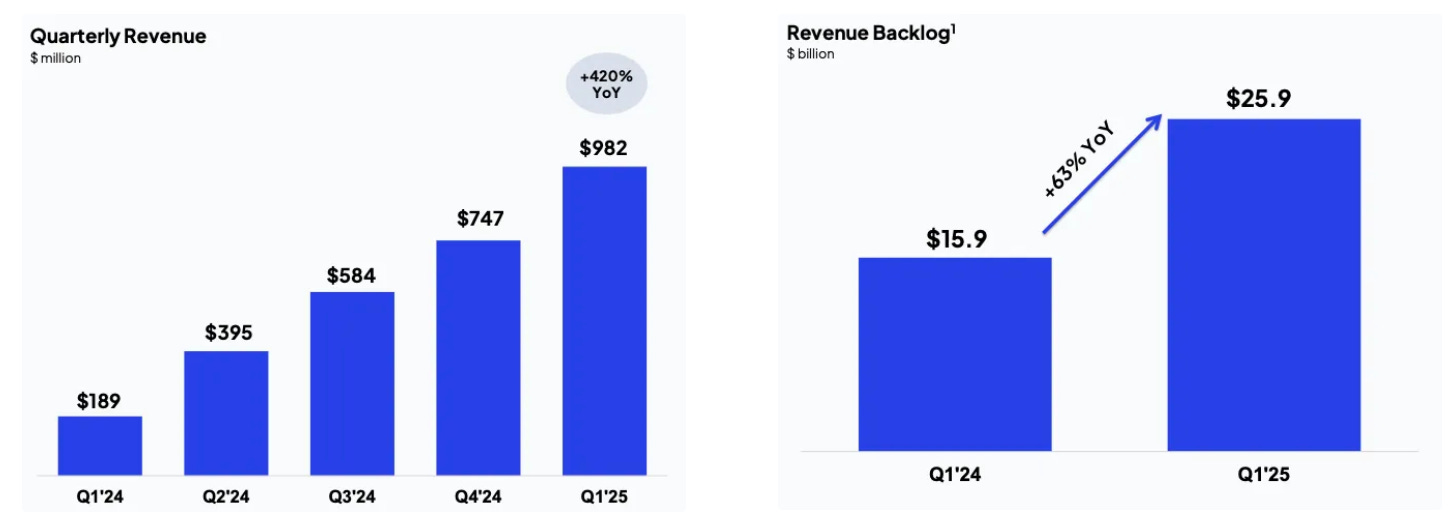
Financial Performance and Risks
A quick look at CoreWeave’s explosive topline growth highlights the rapid acceleration of the AI infrastructure market. Annual revenue has surged from $15.83 million in 2022 to nearly $1 billion in just one quarter (25 Q1). Additionally, CoreWeave’s revenue backlog jumped from $15.9 billion to $25.9 billion in Q1 2025, following a $10 billion deal with OpenAI. More recently, Bloomberg reported another $4 billion contract from OpenAI, pushing the total revenue backlog to approximately $29.9 billion. There’s little doubt that CoreWeave is poised for continued, rapid revenue growth in the quarters ahead.
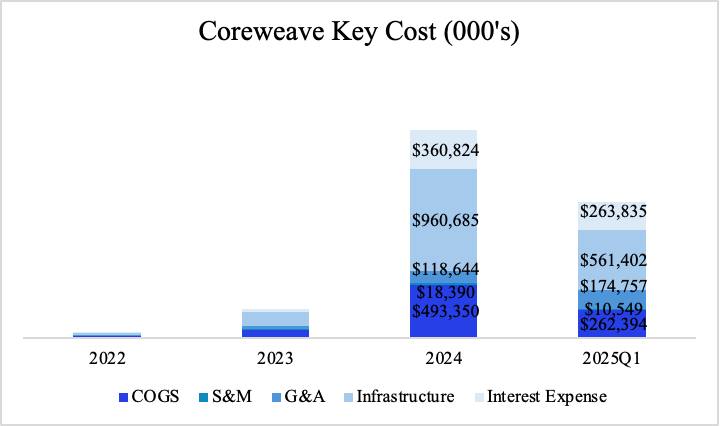
Exploring CoreWeave’s cost structure further reinforces the insights from our unit economics analysis. Costs scale rapidly alongside revenue due to the substantial number of GPUs deployed and the significant expenses associated with operating them. Interest expenses have also surged, driven by increased debt used to finance GPU purchases—mirroring the rise in infrastructure-related depreciation costs.
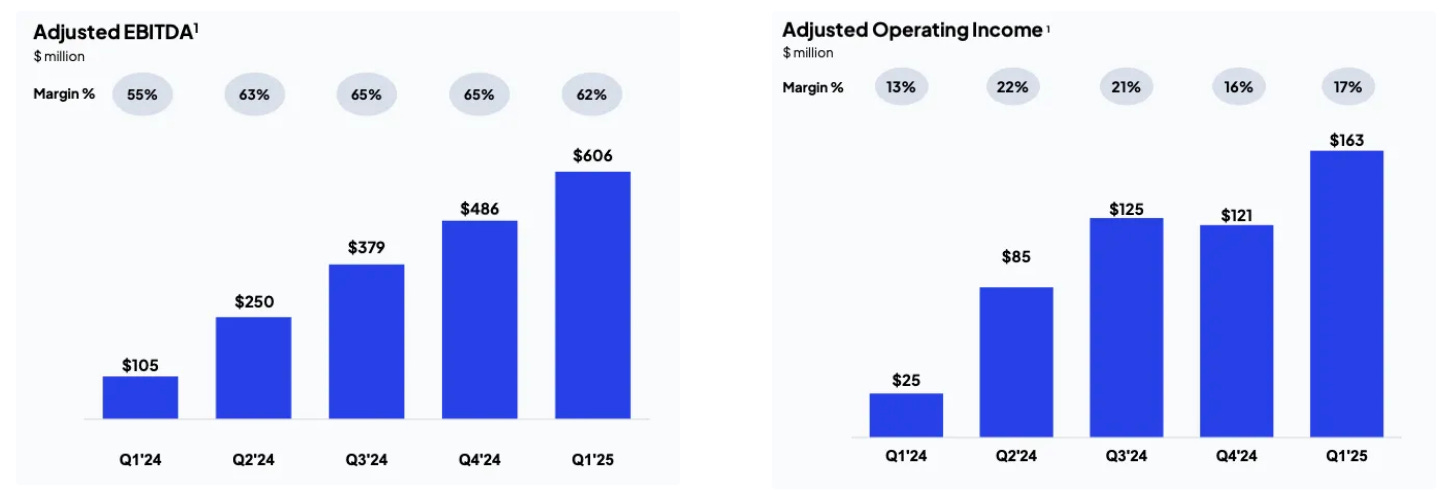
In terms of profitability, both adjusted EBITDA and adjusted operating income margins have increased slightly year over year, indicating that CoreWeave has managed its growth and cost structure effectively.
While CoreWeave is undoubtedly a capital-intensive business, its debt is strategically backed by revenue contracts, with GPUs pledged as collateral. What’s particularly notable is that the debt structure is front-loaded, allowing the company to minimize long-term interest expenses. Importantly, this setup aligns debt repayments with revenue recognition, ensuring that cash inflows from contracts coincide with financial obligations. This disciplined approach to financial engineering reflects the team’s quantitative background and highlights its ability to execute a capital-heavy strategy with precision. Furthermore, as we move into a declining interest rate environment, CoreWeave retains the flexibility to refinance its debt at more favorable rates.
“As of March 31, 2025, the Company had $14.7 billion of unsatisfied RPO, of which 58% is expected to be recognized over the initial 24 months ending March 31, 2027, 40% between months 25 and 48, and the remaining balance recognized between months 49 and 72. This does not include any amounts from the Commercial Agreement with OpenAI”
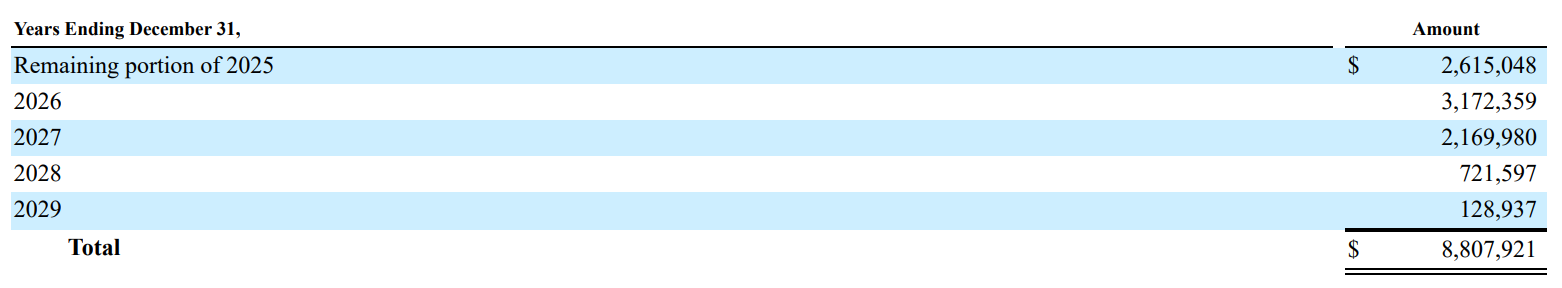
A key risk for CoreWeave is customer concentration—OpenAI and Azure currently represent ~72% of total revenue. Notably, OpenAI has partnered with Oracle to co-build its own datacenter, and Microsoft’s CEO has suggested their CoreWeave engagement was a “one-time” infrastructure deal. However, this risk is partially offset by OpenAI’s massive and ongoing compute demand. It remains the most compute-constrained AI org globally, with aggressive training schedules and high inference volume. OpenAI is also deep in a model development arms race—especially against xAI—making early access to next-gen chips and infra readiness critical. As long as CoreWeave stays ahead on deployment speed and hardware integration, OpenAI is unlikely to shift away materially in the near term.
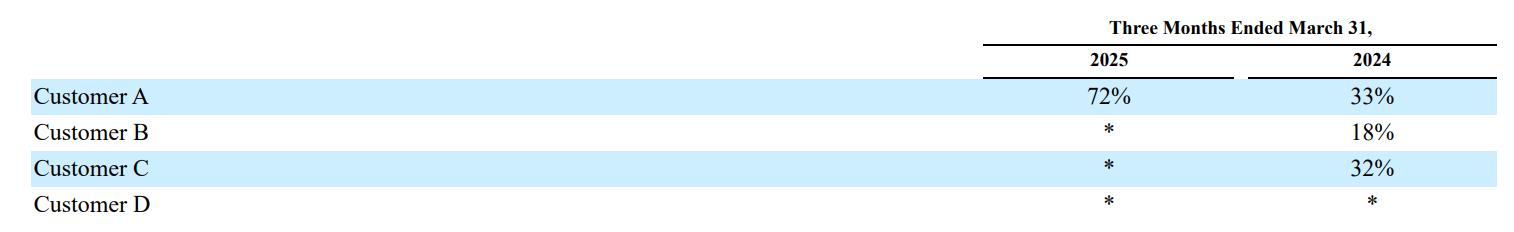
However, we do see CoreWeave noting this risk, as they are signing other hyperscalers and large corporations such as IBM. Furthermore, their purchase of Weights & Biases is not only their desire to move up into the model training stack, but it is also a distribution strategy targeting smaller companies and individual developers. Weights & Biases, a widely adopted MLOps platform used by over 1,400 organizations and hundreds of thousands of ML practitioners, significantly broadens CoreWeave’s reach.

Another interesting aspect of the latest quarterly financials is the growth of CoreWeave’s international business, which has been skyrocketing alongside its U.S. operations. While U.S. revenue grew 425% year-over-year, international revenue also surged by 345% year-over-year. It's worth noting that CoreWeave has been expanding internationally with caution. In 2024, the company established a presence in London (United Kingdom), Barcelona (Spain), and Falun (Sweden), with only 40 MW of operational capacity currently online. Additionally, CoreWeave has contracted data center power in Canada, Sweden, and other unspecified locations. This suggests there is still significant potential for CoreWeave’s continued global expansion.
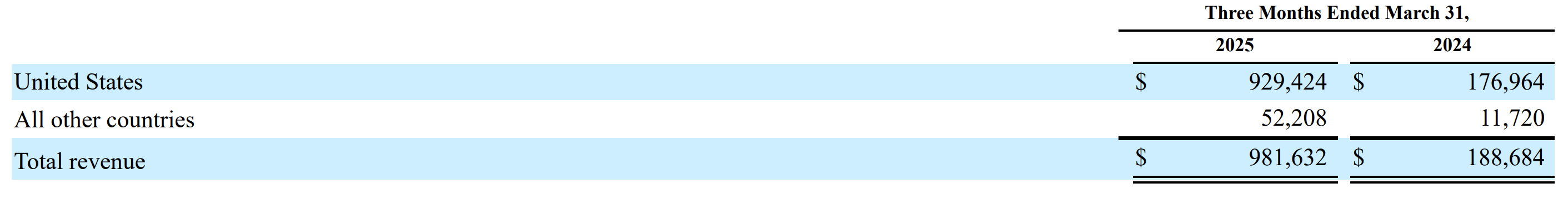
A hot topic currently circulating is the emerging AI compute partnership between the U.S. and the UAE. The agreement has three key components:
A 5 GW data center in Abu Dhabi, developed in partnership with Oracle, NVIDIA, Cisco, SoftBank, and G42. Any data center abroad will be operated by a US cloud provider.
Reciprocal investment: For every dollar the UAE invests in Stargate UAE and the broader Abu Dhabi data center initiative, it will also invest an additional dollar into U.S.-based AI infrastructure projects, including Stargate in the U.S.
Strategic implications: This sets a precedent on multiple fronts—first, the U.S. government is providing a strong framework for compute international expansion; second, it could drive down the domestic cost of capital for data center development.
We view both developments as strong tailwinds for CoreWeave’s ongoing growth, both in the U.S. and abroad.
Valuation - Sanity Check!
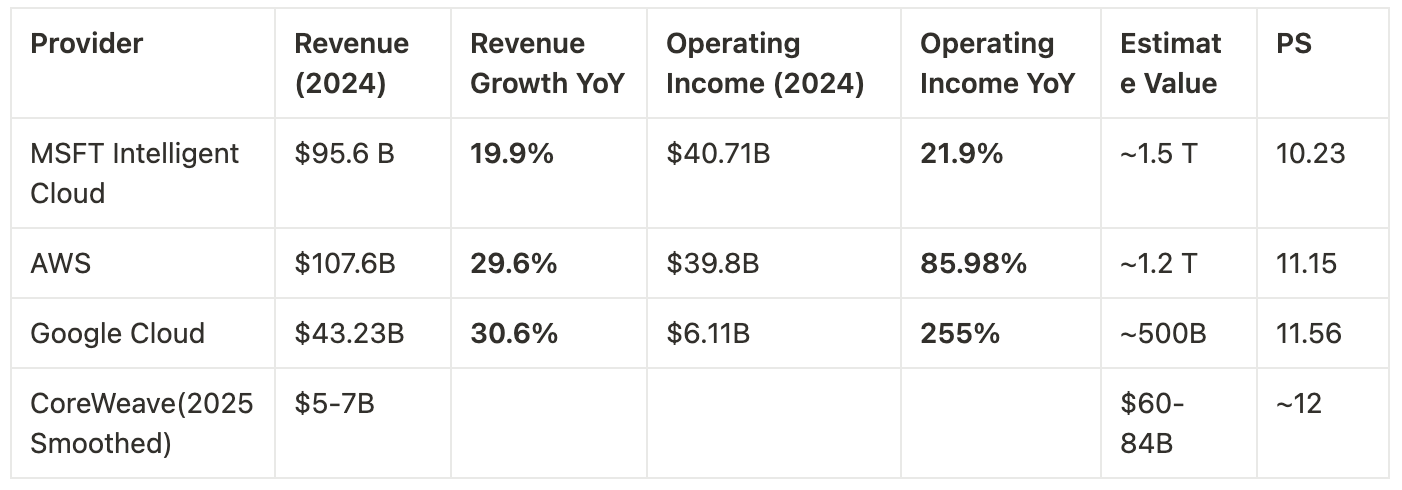
Using comparable comps, we can estimate that the price-to-sales (P/S) ratio for the big three hyperscalers is around 10–12. Based on 2025 consensus revenue (~$5 B), we can calculate an estimated valuation for CoreWeave. If we apply a P/S ratio of 12 to $5 B revenue, this implies a market capitalization of at least $60 billion.
If we consider the revenue backlog as smoothed-out fulfillment, a rough estimate suggests that the $14.7 billion—plus an additional $14 billion from OpenAI—spread evenly over four years would result in an annual revenue run rate of approximately $7.5 billion. We apply a P/S multiple of 12 to CoreWeave, accounting for its high growth but also recognizing its currently concentrated customer base.
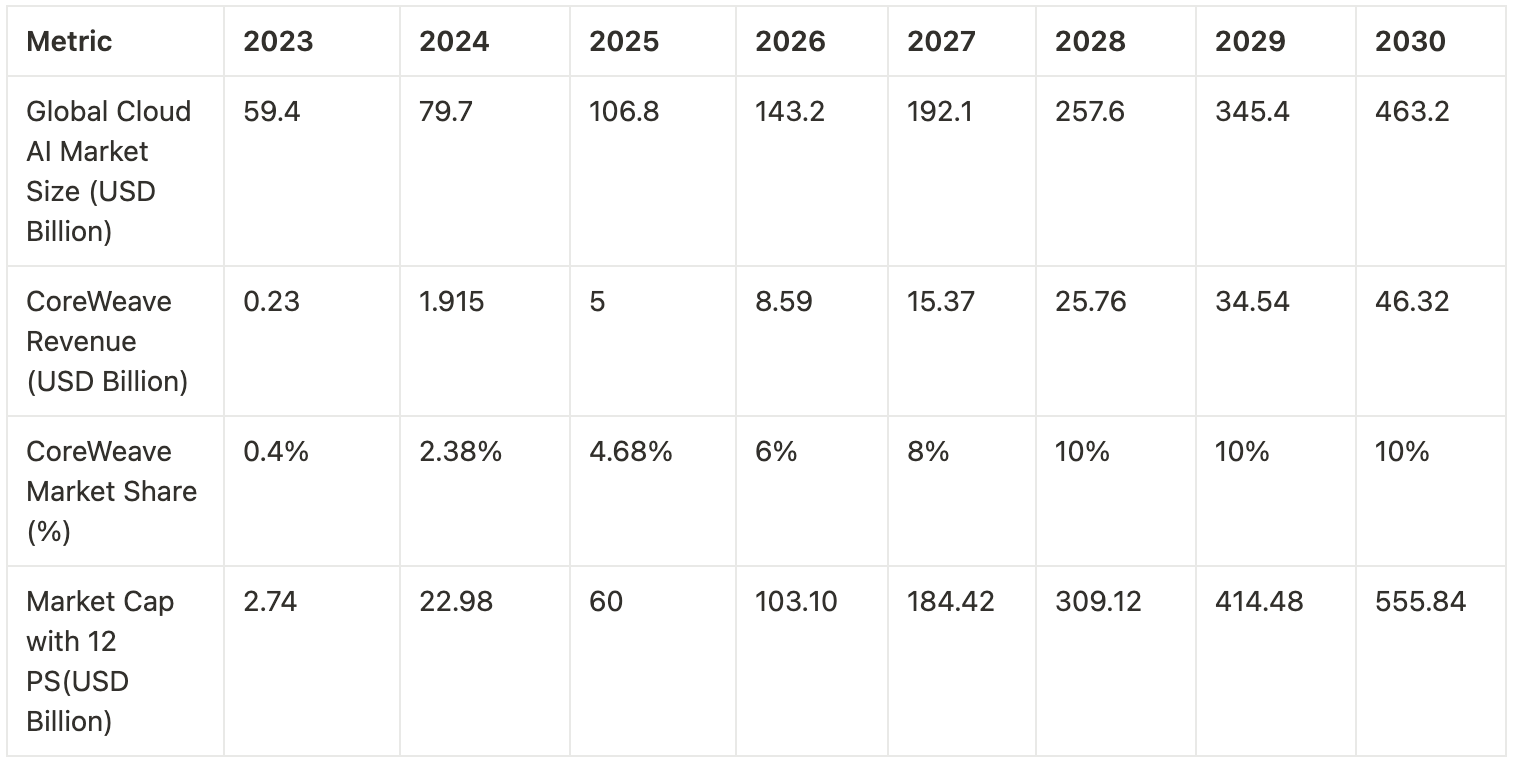
Another method to estimate valuation is based on CoreWeave’s capture of AI cloud market share. From 2023 to 2024, CoreWeave’s market share grew from 0.4% to 2.38%. With an estimated $5 billion in revenue for 2025, its share would rise to approximately 4.68%. Assuming CoreWeave increases its market share by 2 percentage points annually until reaching a stable 10% by 2028, its market capitalization could exceed $500 billion by 2030 (at a constant 12x P/S multiple).
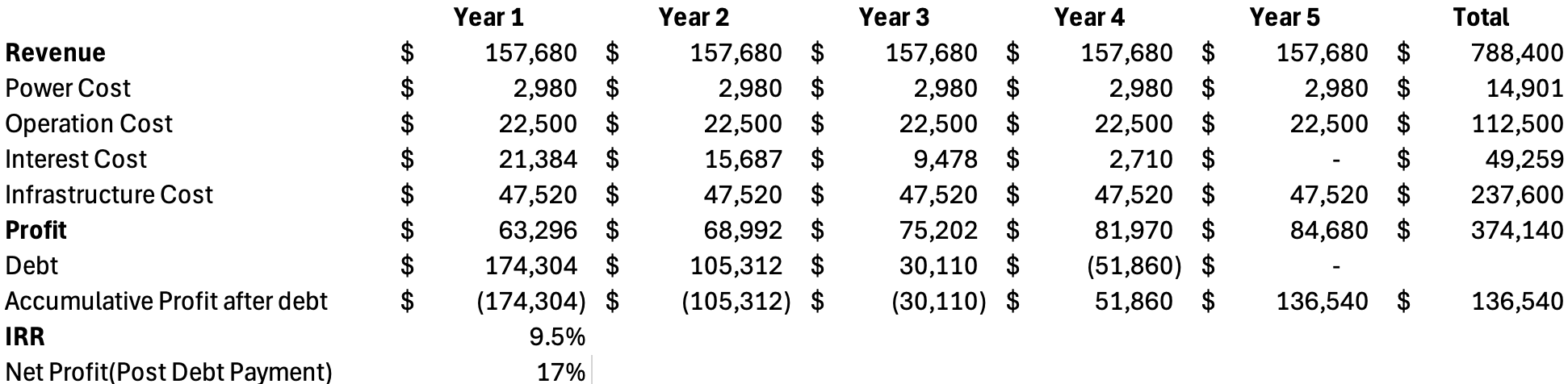
If we use profitability as an alternative valuation method and assume CoreWeave continues to grow while benefiting from economies of scale, we can model a scenario where infrastructure, operational, and power costs each decrease by 10%, and the cost of capital drops to 9%. Additionally, we assume a GPU usage rate of $2.50 per hour and a five-year contract, consistent with the assumptions in our previous simulation. Based on these inputs—and after accounting for debt repayment—the net profitability over the five-year revenue period is estimated at 17.3%. Using the above estimated revenue as a baseline, we will calculate the market cap based on 30 P/E multiple for the next 5 years.
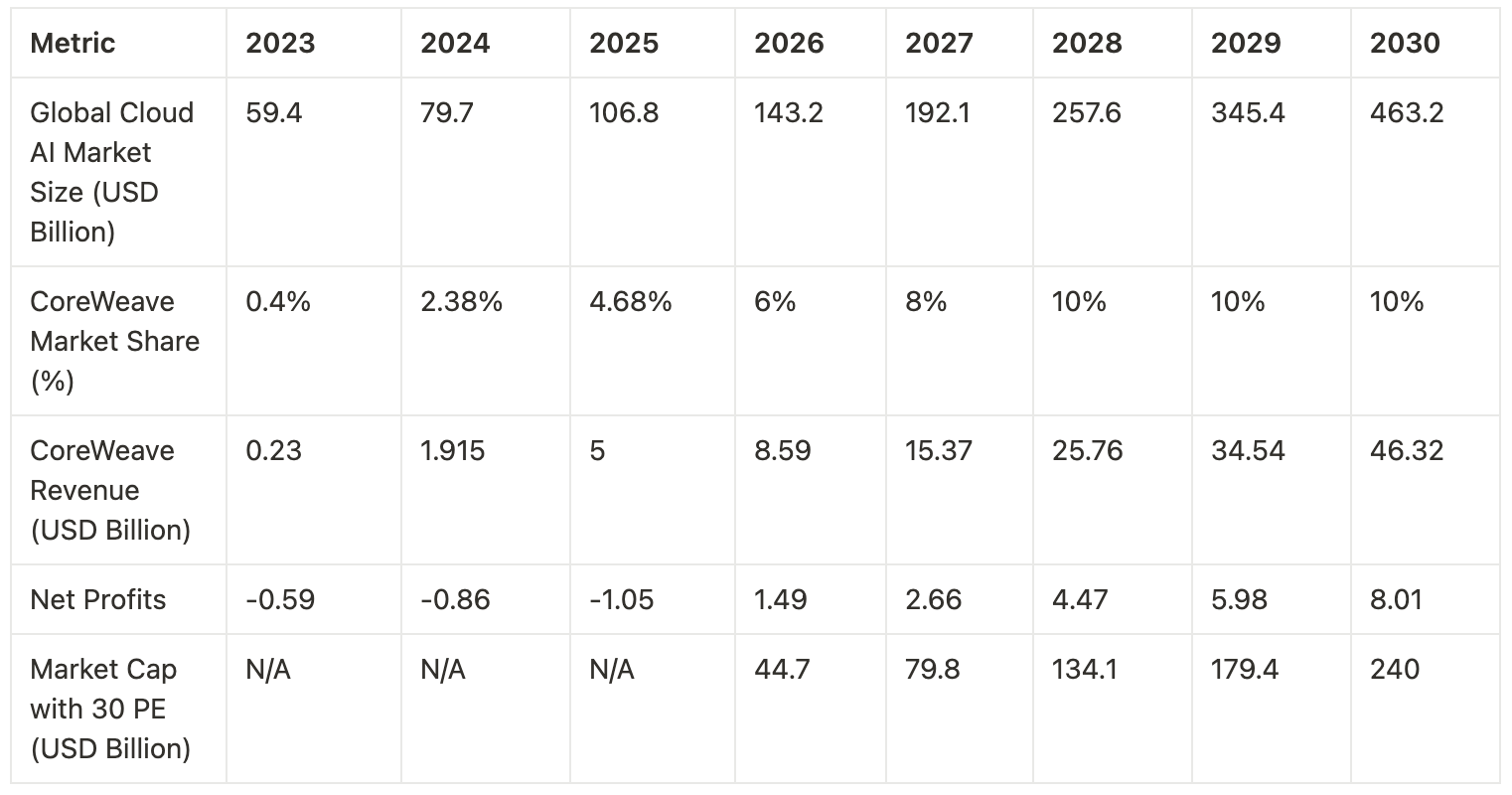
Conclusion:
It’s important to note that even with strong growth, CoreWeave’s long-term viability—and that of the broader GPU cloud sector—ultimately hinges on hardware economics. In this asset-heavy, front-loaded model, falling GPU prices and high interest rates can quickly erode returns. Compressed margins and extended payback periods make new deployments increasingly hard to justify—even for a scaled player like CoreWeave. To build more durable value, CoreWeave must move higher in the AI stack. The acquisition of Weights & Biases is a strategic first step—it positions CoreWeave to capture more of the software and workflow layer, while also expanding its reach into smaller organizations and individual developers. If CoreWeave can transition from a GPU infrastructure provider into a full-stack AI platform, it will be far better positioned to defend margins and create long-term value in a sector where hardware alone is becoming increasingly commoditized.
Sources:
CoreWeave. (n.d.). CoreWeave S1 filing. Retrieved from company filings or investor relations (exact URL or SEC EDGAR link if available).
CoreWeave. (2025). Form 10-Q for the quarterly period ended March 31, 2025. Retrieved from company filings or SEC EDGAR database.
SemiAnalysis. (2025, March 26). The GPU cloud clustermax rating system: How to rent GPUs. Retrieved from https://semianalysis.com/2025/03/26/the-gpu-cloud-clustermax-rating-system-how-to-rent-gpus/#applying-the-semianalysis-tco-framework-to-coreweave
NVIDIA Corporation. (n.d.). Official website. Retrieved from https://www.nvidia.com/
Market.us. (n.d.). Cloud AI Market Size, Share | Industry Report [2024–2033]. Retrieved from https://market.us/report/cloud-ai-market/
The Guardian. (2025, May 15). Trump, artificial intelligence, and the UAE. Retrieved from https://www.theguardian.com/us-news/2025/may/15/trump-artificial-intelligence-uae
AlphaSense transcript of expert call with a former Amazon VP (April 11, 2025). Excerpt reproduced with permission. © AlphaSense Inc. All rights reserved.
AlphaSense transcript of expert call with a Latitude engineer (May 19, 2025). Excerpt reproduced with permission. © AlphaSense Inc. All rights reserved.
AlphaSense transcript of expert call with a General Manager at Supermicro (May 25, 2025). Excerpt reproduced with permission. © AlphaSense Inc. All rights reserved.
AlphaSense transcript of expert call with the CEO of Cerebrium (May 26, 2025). Excerpt reproduced with permission. © AlphaSense Inc. All rights reserved.
Apoorv Agrawal. (2024, April 25). The economics of generative AI.